架构之流量控制
防患于未然,胜于亡羊补牢。
任何软件系统都不可能具有无限的资源,都具有其相对应的最大承载能力。如果你的系统也有可能面对突发的大流量,就需要考虑流量控制。
我们常见的微服务设计中,经常将系统拆解成多个服务,共同对外服务,其内部可能有较长的调用链。那么整体系统的可用性是由这个链条上的所有节点的可用性决定的,因此:
整体可用性 = Service1(可用性) * Service2(可用性) * … * ServiceN(可用性)
如果这个链条上有10个服务,每个服务的可用性为99%,那整体系统的可用性将是90%左右!
我们构建微服务的一个目标就是提高容错性。事实上,如果中间某一个服务崩溃不可用,后续还有不断的流量进入系统,很可能会殃及其它的服务一起崩溃,最后导致连90%都不能达到。
所以我们要对系统进行流量控制,也就是常说的限流(限制流量),目的是保证即使某几个服务出问题或者突发的大流量,系统仍能对外提供服务。
熔断降级限流
继续限流之前,系统设计中,还有几个容错的手段也是经常提及,就是服务降级和熔断模式。
服务降级:在一些关键场景(比如搞大促销,秒杀),将一些非关键服务或者次要功能停掉,优先将有限的资源保障给关键服务。
熔断模式:它是一种保护服务免受级联故障影响(雪崩)的设计模式。当某个服务出现故障或响应延迟过高时,熔断器会临时切断对该服务的调用,避免故障扩散。后续定期尝试恢复对故障服务的调用,并在服务恢复正常后重新打开调用链路,因此系统具备了”自愈“功能。
这降级,熔断,限流三个策略会经常放在一起讨论处理,这里我们简单对比下它们的差异:
- 差异1: 降级并不一定是在大流量到达后才启用的手段,它可能是一种带有目的性(比如为大促销活动,提前关闭评论功能)的预防手段;熔断和限流则是在系统真正负载过高后触发的!
- 差异2: 降级的方式有很多,可能根据业务场景不同而不同。比如停用评论功能,将数据的强一致暂时调整为最终一致性,系统由返回全量数据暂时改为返回一部分数据等等,这些都属于降级措施 。熔断则可以看作降级的一种特殊方式,它利用快速失败(FailFast)的方式,将错误快速的返回给调用方,因此调用方需要处理这种错误。
- 差异3: 降级和熔断都是应对措施,而限流则是预防措施。我们提前设置一些系统的阈值(QPS,最大线程数,最大在线用户数等等),在系统运行过程中如果触发这些阈值,则触发限流,对额外的流量进行旁路处理(可以是记录到日志,也可以直接返回429状态码等等)。
三种策略都是保证系统的可用性手段,但是切入点不同而已。
限流方式
令牌桶算法-Token Bucket
令牌桶限流实现方式大致是这样的,每隔固定时间,将一批新的令牌(具体令牌个数可以配置)放到令牌桶中,每个请求需要从桶(Bucket)中获取到一个令牌才能被处理 ,如果桶(Bucket)没有令牌,则该请求需要被丢弃或进入旁路处理。
漏桶算法 – Leaky Bucket
对于漏桶算法,大家则可以把它想象成一个液体漏斗,不管多大的水量流入漏斗,都是以一个恒定的速率被处理。
这两种算法虽然不同,但殊途同归实现了差不多的效果,也比较容易搞混淆,见下图(图片来源网络):
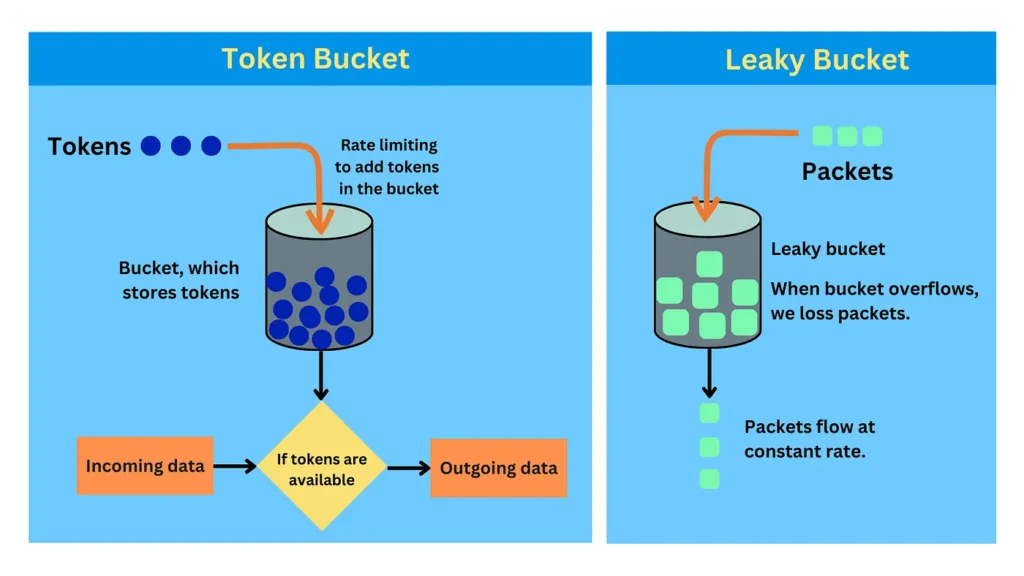
接下来,我们再对比下它俩的区别和联系:
- 两者都可以基于队列实现,对于排队的请求来说,都是阻塞式的,会有线程切换。
漏桶算法:将请求放入队列排队,然后消费者按照自己的固定频率(根据阈值设定)消费,当队列满了,则请求丢弃或进入旁路处理。
令牌桶算法:同样将请求放入队列,一旦请求能被分配到令牌,则被立马处理,如果没有令牌,则继续排队;当队列满了,则请求丢弃或进入旁路处理。 - 面对突发流量时,两者最终都是设定好的阈值速率来处理请求,结果相同,但是过程不同。
- 由于在低峰流量时,令牌桶中可能有一批富裕,面对突发流量时,前期一段时间内请求处理量会大过设定的阈值,但随着令牌消耗殆尽,则回归到阈值附近。
- 面对突发大流量,漏桶算法则没有上述的”尖峰“时刻,流量上升到相对平稳的阈值范围内。
计数器算法
这种方式比较简单,如果我们设定1秒内最大处理10个请求,那可以用一个计数器(Counter),统计当前一秒内的请求个数,如果大于10个,则拒绝额外的请求。
很明显,它的缺点是时间划分是离散的,很可能在1.5秒到2.5秒这一秒内的请求已经超过10个请求了。为了修补这个BUG,一种更好的滑动窗口算法被提及。
滑动窗口算法 – Sliding Window
很像TCP协议的滑动窗口思想。假设还是1秒内最大处理10个请求,设置一个大小为1秒的滑动窗口,内部划分有多个格子,随着时间的推移,窗口格子会往前移动,从而丢弃最早的时间格子,每个格子内部记录着当前时间段内的请求统计值(请求次数,成功次数,失败次数等等),最后每个格子的统计值相加就能获取当前周期内的请求个数。 图片来源于网络
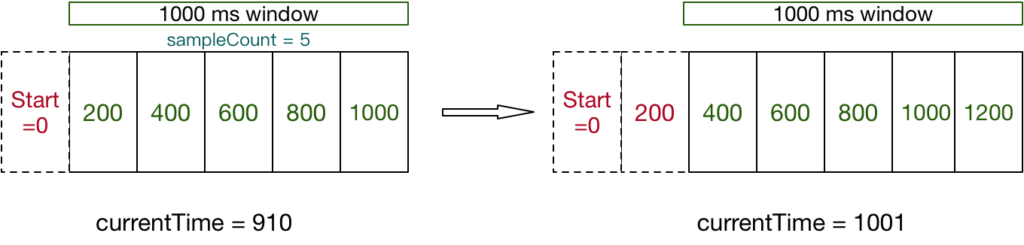
窗口格子划分越细,则越准确,但消耗的内存资源更多。
源码探讨
最后,我们以滑动窗口算法为例子 ,从Sentinel框架简单看下它对滑动窗口的实现。如果你想了解令牌桶算法,可以参考Guava的RateLimiter实现。
实现滑动窗口并不真正需要一个很大的数组,只需要配置一个固定格子数的数组,对于丢弃最早的时间格子行为,其实就是进行数组数据覆盖即可。滑动窗口,Sentinel内部对应是一个LeapArray。
public abstract class LeapArray<T> {
// 单个格子的时间跨度,用intervalInMs/sampleCount得到
protected int windowLengthInMs;
// 格子个数
protected int sampleCount;
// 间隔时长
protected int intervalInMs;
// intervalInMs/1000得到
private double intervalInSecond;
// 窗口数组,用atomic保证操作的原子性
protected final AtomicReferenceArray<WindowWrap<T>> array;
}
如果想要知道当前的时间,时间窗口应该是处于哪个数组下标(即格子),如下:
private int calculateTimeIdx(/*@Valid*/ long timeMillis) {
long timeId = timeMillis / windowLengthInMs;
// Calculate current index so we can map the timestamp to the leap array.
return (int)(timeId % array.length());
}
即:用当前时间戳除以格子的时间跨度,最后模上数组长度。这样可以将当前时间戳,按照格子时间跨度进行整形(表示时间戳经历了多少个单位格子的时间间隔)。
当前时间模格子时间跨度,得到在窗口起始位置的偏移量,这样可以估算当前格子的起始时间:
protected long calculateWindowStart(/*@Valid*/ long timeMillis) {
return timeMillis - timeMillis % windowLengthInMs;
}
最终到统计值的维护,内部则是用了LongAdder来实现,对比AtomicLong而言,它利用分散竞争方式,使得高并发下统计更高效。
public class MetricBucket {
private final LongAdder[] counters;
private volatile long minRt;
}