架构之全面认识缓存
对于缓存,我相信大家都不陌生,如果你是一名程序员,可以问下自己这样一个问题:
你目前开发的系统中,哪里用到了缓存?为什么要引入缓存?如果系统中去掉缓存系统,对于整个系统会带来什么好处和坏处?
如果从软件和硬件的整体来看我们的系统,缓存的使用几乎无处不在。
- HTTP的请求中可以约定缓存,请求头部Cache-Control就是用来控制缓存;
- CDN是一种缓存,缓存静态的资源,保护源站;
- Nginx可以配置proxy_cache定义代理缓存,进程中的Map,List亦可作为缓存;
- 消息队列可以看作一种缓存,将数据缓存在一个独立的系统中,以便各个上下游处理;
- Redis,Memcache等常常作为分布式的缓存系统,在系统中独立扮演缓存角色;
- 数据库系统的Buffer缓存,操作系统的页缓存,CPU中的L1 L2 L3缓存
- ……
接下来,我们主要还是围绕服务端系统中的缓存来讨论。
大家一个普遍的看法就是,引入缓存提高了响应性能。这种说法并没有问题,从本质上缓存它只是让数据更加靠近使用者,从而缓解了CPU的压力和IO的压力,结果就是带来了性能的提升,毕竟它是一个典型的空间换时间的例子。
缓存分类
从分类来讲,缓存分为进程内缓存和分布式缓存。
- 进程内缓存的选择有很多,比如JDK自带的ConcurrentHashMap,开源的有Ehcache,Guava Cache以及Caffeine等等。
- 分布式缓存也有像Memcache和Redis为代表。
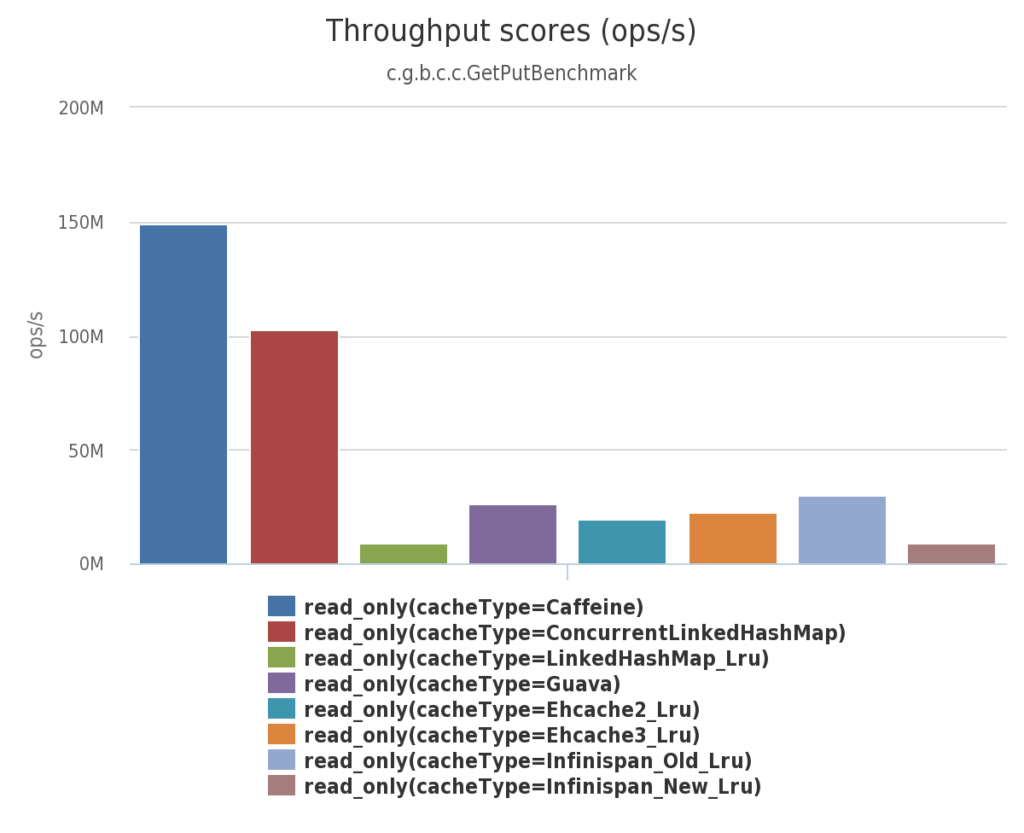
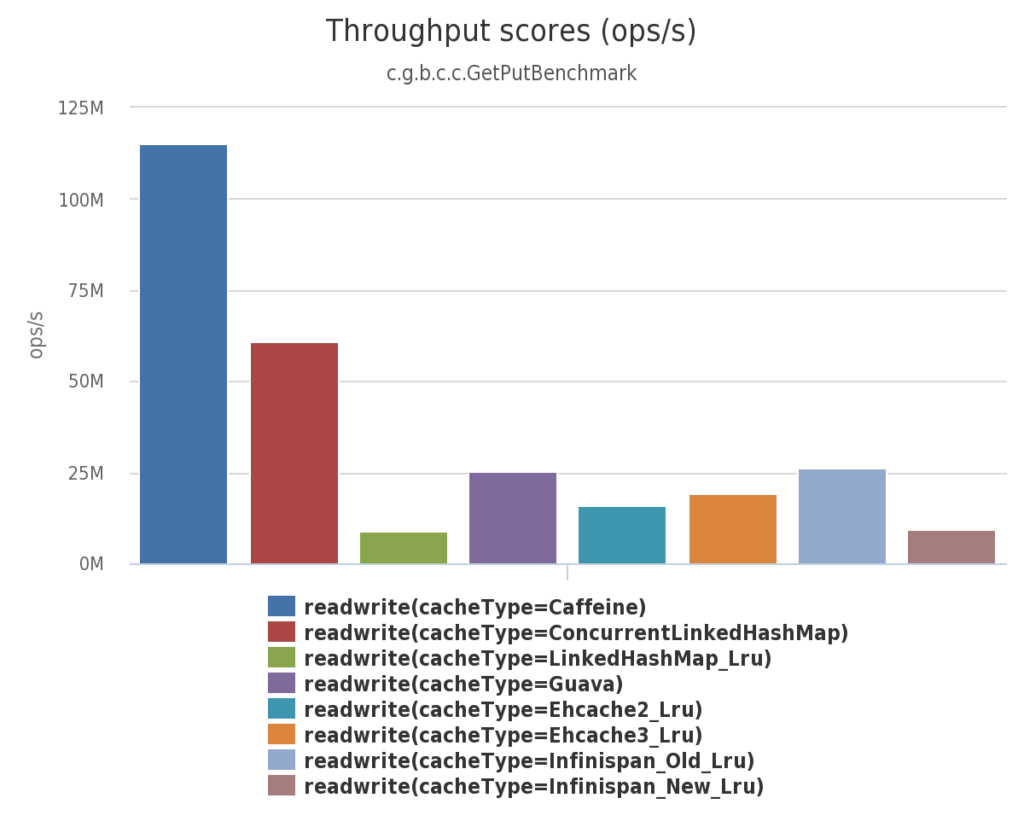
对于进程内缓存的几种框架的性能对比, 借用Caffeine的Benchmarks报告:
100%的读场景:
读 (75%) / 写 (25%)场景
100%写场景
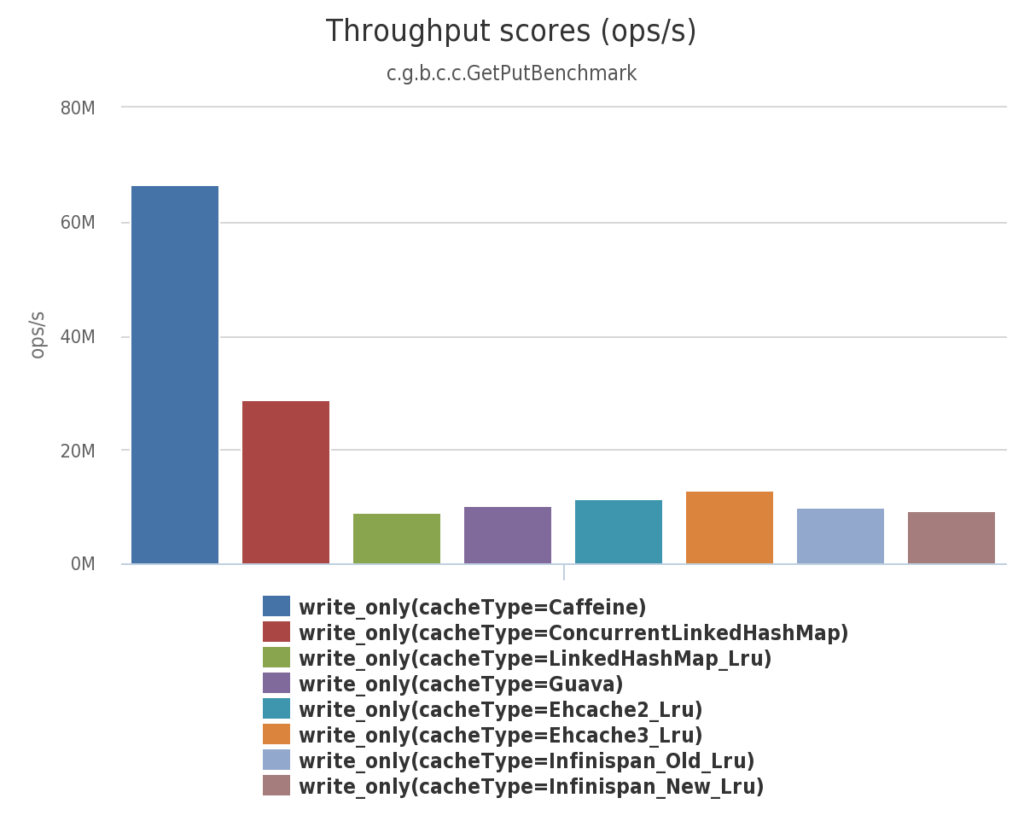
从图片可以看出,Caffeine已经成为事实上的性能最高的进程内缓存开源组件。
接下来再对比下两种分布式缓存Memcached和Redis:
| 特性 | Memcached | Redis |
|---|---|---|
| 亚毫秒级延迟 | 是 | 是 |
| 开发人员易用性 | 是 | 是 |
| 数据分区 | 是 | 是 |
| 支持多种编程语言 | 是 | 是 |
| 高级数据结构 | – | 是 |
| 多线程架构 | 是 | – |
| 快照 | – | 是 |
| 复制 | – | 是 |
| 事务处理 | – | 是 |
| 发布/订阅 | – | 是 |
| Lua 脚本编写 | – | 是 |
| 地理空间支持 | – | 是 |
缓存的属性
再考虑使用缓存时,我们会重点考虑它的性能(吞吐量)和命中率两种属性
性能
从上面的图可以看到,对于进程内的缓存,Caffeine比较好;分布式缓存Redis和Memcached的读写性能都不错,都是亚毫秒级别,但是redis支持的数据结构更多,并且天然支持快照持久化。
进程内缓存
如果是简单的KeyValue对缓存,并且数据量不太大,我们完全可以使用ConcurrentHashMap,在保证多线程安全方面的前提下,它是我们能找到的性能最佳选择,其内部对元素进行无锁CAS的操作。
如果业务复杂,需要更多功能。比如需要根据缓存写入时间或者缓存读取时间对数据进行过期删除;限制缓存最大容量并提供合适的数据删除策略;提供缓存的统计信息,比如命中率;有事件通知策略,能够监听数据失效刷新等,那可以考虑Caffeine。
为什么Caffeine的性能会比较好,我们从它的设计上可以看出一些端倪。
- 从本质上Caffeine内部仍然用ConcurrentHashMap来缓存数据。
- 为了满足过期删除,淘汰等功能,需要对缓存数据维护额外的统计值,比如最近的访问时间(accessTime),写入时间(writeTime),访问次数(increment)等。对于这些功能,Caffeine模仿数据库的预写机制,数据的变更和读取事件分别存入writeBuffer和readBuffer中,然后利用异步线程来读取Buffer更新统计值。
readBuffer本质上是一个环形缓冲区,代码上就是一个有界数组模拟环形,它的好处就是内存友好,并且消除消费者和生产者竞争,为了进一步的消除竞争,每一个线程单独使用一个环形缓冲区(即:对线程取 Hash,哈希值相同的使用同一个缓冲区)。在缓存的场景中,读的频率是非常高的,readBuffer数据插入频率很可能大于消费速率,如果仅仅用阻塞队列来实现该需求,就不得不有锁等待导致线程挂起从而性能严重损耗。如果是环形缓冲区,只需要写入和消费线程各自维护自己的数组索引位置即可(readCounter和writeCounter)。当writeCounter追上了readCounter,说明缓冲区满了,Caffeine允许读事件的丢失来维持高性能。 其内部没有任何锁机制,并且对readCounter和writeCounter加入Padding值来规避CPU伪共享进一步提高性能。
writeBuffer则是一个有界队列(ArrayQueue)。不用环形缓冲区是因为读事件允许丢失,但是写事件绝不能允许丢失。它借鉴了JCTools中的多生产者单消费者(Multiple Producer Single Consumer, MPSC)的实现。能不同样是采用了分离生产者索引(producerIndex)和消费者索引(consumerIndex)以及避免伪共享方式来提升性能。 - 对于缓存的访问计数,Caffeine 使用了 基于CountMin Sketch的W-TinyLFU算法来淘汰数据,CountMinSketch本质上是在节省内存的基础上,来近似的计算每个元素的频率。对key进行多次 hash 函数运算后,对应二维数组不同位置存储频率加1,Key的频率则对应每个位置上的频率值,取最小值返回。见下图:
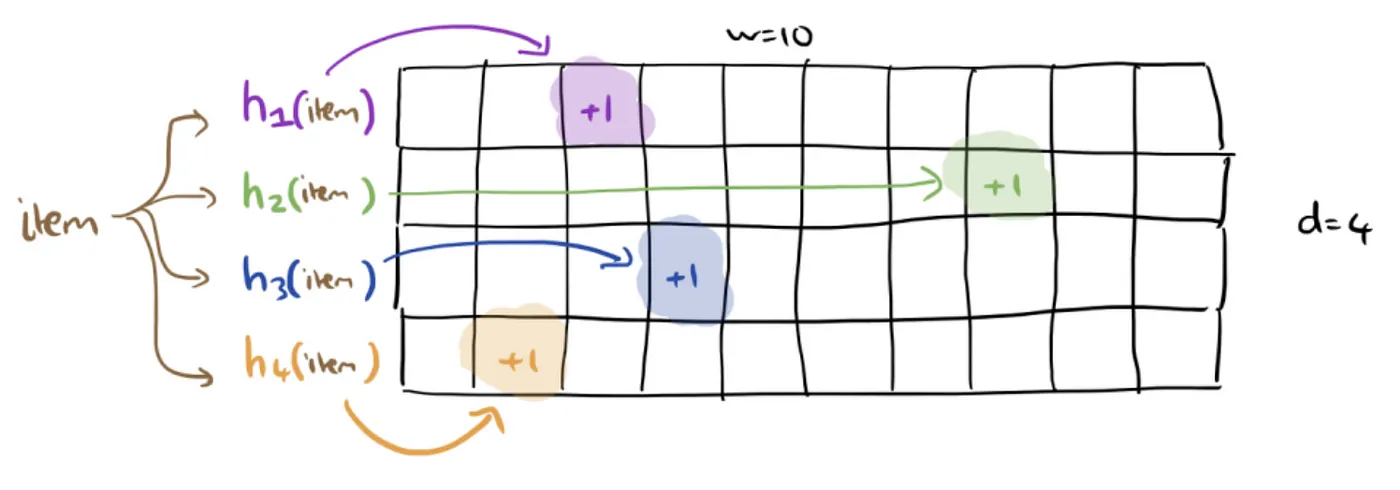
为了保证某些热点不再是热点数据情况下,未来能够被删除,会定时对所有元素的频率次数除以2,达到降级效果。 - W-TinyLFU中设计中,将容量划分为三个主要区域(Window、Probation和Protected)来实现高效的缓存管理。
Window区域:主要作为新进入缓存项的”接待区”,使用LRU(最近最少使用)策略管理,可以用来捕获突发性的稀疏流量。
Probation区域:当Window区域满时,最老的项会被降级到Probation区域,评估缓存项是否有资格进入Protected区域,使用TinyLFU频率筛选机制。当Probation区域满时,会与Protected区域的候选者进行”淘汰赛”,新来的项与Protected区域最老的项进行频率比较,胜者进入Protected,败者被淘汰或者降级。
Protected区域:被确认为热点的缓存项,为高频访问项提供长期保护。这种三区域的结构能够同时很好地处理突发性流量和长期热点流量。 - 复杂的定时任务淘汰策略,又引入了时间轮(TimeWheel)算法来实现。
分布式缓存
对于Redis和Memcached,要想理解它们的性能表现,我们就要知道它们各自的网络模型。
Redis是典型的单线程,基于事件驱动模型的网络多路复用模型。所有用户的请求都是在一个线程中处理,因此大部分情况能够保证操作的顺序性。
Memcached采用多线程,以及非阻塞的IO模型。主线程来处理客户端的连接,工作线程来处理用户的请求。因此Memcached能够更好的利用多核的优势。
在就目前我的观察来看,由于Redis单线程具备更少的上下文切换,高并发情况下,它也能够维持在略低于Memcached的吞吐量上工作,但是客户端连接数多,请求量大,单线程终究是一个瓶颈,导致响应时延会比Memcached高一个数量级。
因此在产品决择时,你需要问自己是否真的需要redis其它的扩展功能?
缓存的隐患
天底下没有100%命中率的缓存,除非有无限大的空间。作为系统架构,我们始终要保持一个谨慎的心态。增加一个组件,能够享受它的收益,同时就会带来其它的风险,这需要仔细的考量。
缓存穿透—Cache Penetration
缓存不命中情况下,最终会请求数据源查询。对于大量查询了不存在的Key,而导致请求末端的数据源,我们称之为缓存穿透。注意:不存在的Key表示数据库也没有。
缓存穿透有可能是代码问题或者恶意的攻击行为。对于解决方案,我们可以对不存在的插入空key进行缓存,一段时间内最多穿透一次。恶意情况下,还有必要设置一个前置的过滤器,比如布隆过滤器。
缓存击穿—Cache Breakdown
缓存击穿则是:某些热点数据如果某些原因全部或者大部分失效,导致大量到达数据源,导致压力剧增。典型的原因,比如由于超期时间而失效,此时又有多个针对这个热点数据的请求。
解决方法:
- 互斥锁(Mutex Lock):只允许一个线程重建缓存,其他线程等待或返回旧数据。
- 手动更新管理:如果是由于自动失效导致的,可以热点Key设置为永不过期,通过后台任务定期刷新。
缓存雪崩—Cache Avalanche
雪崩:大量缓存数据失效,或者服务崩溃重启,此时所有的请求都将落到数据源中,导致数据源一起崩溃。
解决方案:
提升可用性,高可用设计
- 多级缓存:结合本地缓存(Caffeine)和分布式缓存(Redis),即使Redis崩溃,本地缓存仍可部分拦截请求。
- 集群容灾:使用Redis Sentinel或Cluster模式,避免单点故障。
分散过期时间,避免Key集中过期
- 差异化过期时间:在基础过期时间上增加随机值(如
TTL = 基础时间 + 随机1~5分钟)。 - 分层过期:对不同类型的Key设置不同的过期策略。
熔断降级
- 限流机制:通过Hystrix、Sentinel等工具限制数据库访问流量。
- 降级策略:缓存失效时返回默认值或兜底数据(如旧缓存、静态页)。
上述的三种缓存隐患常常容易混淆,因此我特地加上了英文表述,并且为了进一步加深印象,总结了下表:
| 维度 | 缓存穿透 | 缓存击穿 | 缓存雪崩 |
|---|---|---|---|
| 触发条件 | 查询不存在的数据 | 热点Key突然失效 | 全局或大面积Key |
| 数据存在性 | 数据库本就不存在该数据 | 数据库存在,但缓存失效 | 数据库存在,缓存失效 |
| 并发量 | 可能低也可能高(看攻击强度) | 高并发请求集中访问一个Key | 大量Key同时失效或缓存宕机 |
| 解决方案 | 布隆过滤器、缓存空对象 | 互斥锁、逻辑过期 | 提高可用性,分散过期时间,熔断降级 |
缓存一致性
缓存本质是数据冗余,冗余就会有数据不一致现象!大部分情况,虽然缓存和数据源很难保障强一致性,但是要保证最终一致性!对于一致性的保证,有很多设计模式可以借鉴。
缓存模式
Cache Aside
缓存旁路模式。也是一种懒加载的模式。应用程序要和缓存系统以及数据库同时交互!
- 读数据时,先读缓存。没有再读数据源,并且写回缓存,再响应请求。
- 写数据时,先写数据源,然后将缓存失效(不直接更新缓存)。
Read Through
读操作的缓存回填交给缓存系统,即如果缓存不命中,则缓存系统直接从DB中获取数据。应用程序不需要和数据库交互
Write through
写操作同时更新缓存和DB,保证了数据的实时性。但是增加了一致性的复杂度,毕竟同时更新两个系统,相当于分布式事务。
Write behind
先写缓存,再异步通知到DB更新。可以极大提高写的效率,但是增加了数据更新延迟,导致数据更新的丢失。
大多数情况,Cache aside都是一个比较好的模式。
进程内缓存一致性
对于分布式缓存系统而言,它们内部大多支持数据的分片和复制,来保证数据的最终一致性(比如Redis的AP模型,Sentinel,Cluster机制)。
进程内的缓存由于缺少节点间的通信和交互,很容易导致节点间缓存不一致。在构建进程内缓存时,一定要考量一致性的因素,如果一致性高度敏感,就要考虑转换成分布式缓存。但也有一些方法来构建节点间的一致性:
- 单节点处理写请求,然后通过rpc通知其他节点更新。
- 事件驱动方式。引入MQ,单节点处理数据写请求后,异步广播通知更新其他节点。
- 放弃实时一致性,每个节点各自定时更新缓存数据。
方案1和方案2的虽然具备强一致性要求,然而节点多的情况下,通信成本和原子性保证困难。
一致性的其他问题
本身来说,缓存加入,数据的冗余肯定会导致数据不一致。现在大多数底层的数据库都采用了读写分离,主库从库数据同步的方式,这些方案都会进一步加剧缓存不一致的扩散。比如,缓存失效去DB查询数据,此时主从库同步并没有完成,查询从库仍然可能缓存了脏数据。
这里有一种方案可以借鉴:二次淘汰法。
- 第一种,异步方法。第三方工具来订阅从库的binlog,完成同步后,再失效掉缓存。或者服务启动一个Timer,服务删除缓存。
- 第二种,缓存设置过期时间,未来仍然有机会修正数据,代价就是这段时间内的数据不一致。
综上,我们在缓存的使用过程中,我们仍然要基于底层DB的特性来做进一步设计和考量!